Rewriting the santa-lang Interpreter in Rust, Part 4 - Distribution
Now that the interpreter’s performance concerns had been addressed, it was time to decide how each of the available runtimes would be packaged and distributed. In the final post within the series, I will document how the language and runtimes were built, tested, and distributed using a custom CI/CD pipeline.
Pipeline
As documented in a previous post, the project has been structured as a monorepo Cargo workspace, with the language and runtimes being separated into different packages. This allows the packages to be built and tested in isolation from one another. To provide a deterministic build and release process, I created a CI/CD pipeline using GitHub Action workflows. I also opted to add a GitHub Action called Release Drafter to the project. This provides automatic collection and creation of relevant release notes and semantic versioning based on merged GitHub pull requests (and tags).
I thought the best way to describe this pipeline was visually.
Below is a diagram depicting the journey of a change that has been merged into the main branch, being built, tested, and distributed to relevant external package managers:
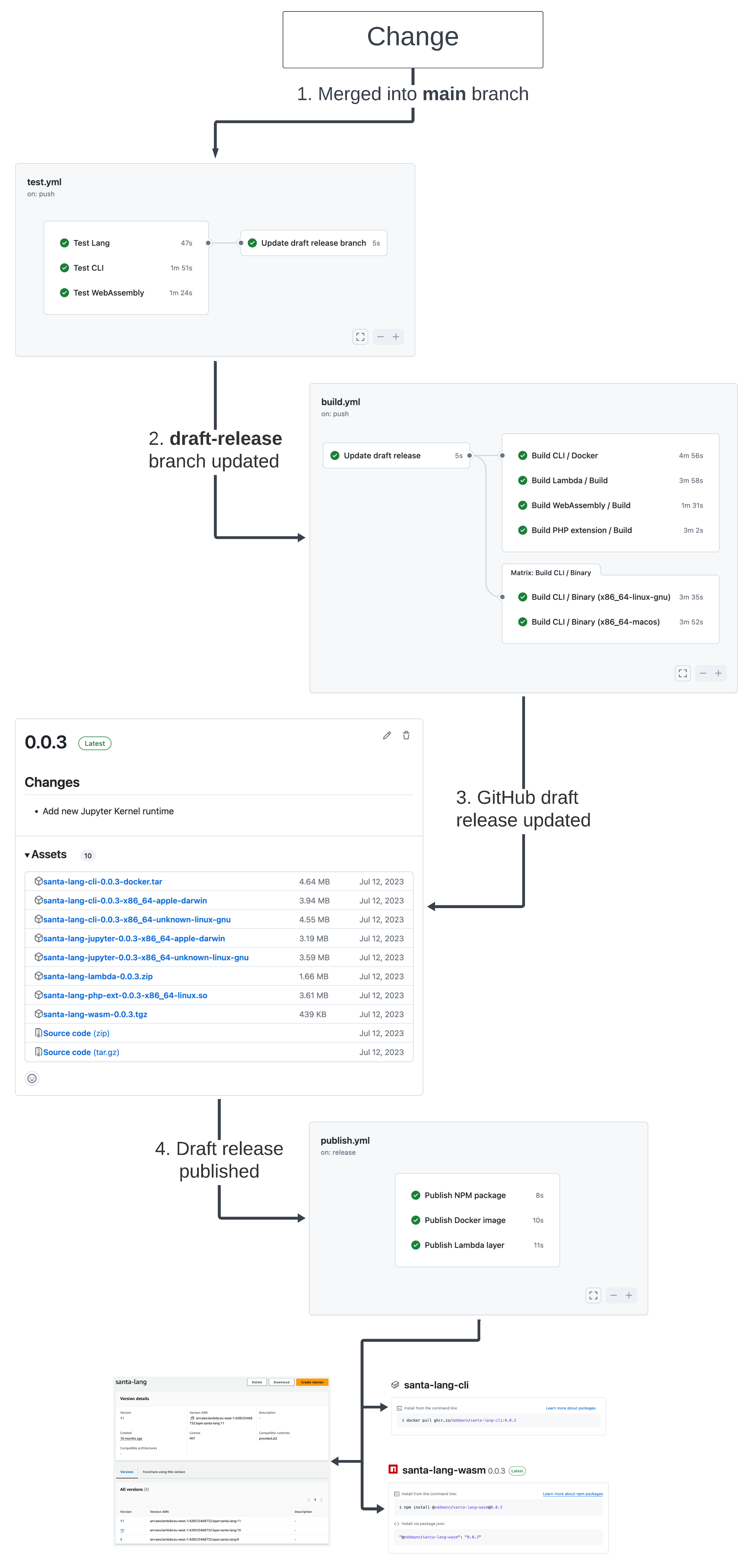
- Once a development branch is passing, it can be merged into the
mainbranch. Once merged, the test suite is run (again), and thedraft-releasebranch is updated to point to this merged commit. - Upon changes appearing in the
draft-releasebranch, the draft GitHub release notes and version are created/updated using Release Drafter. From here, the runtime binary artefacts are built and attached to the draft GitHub release. - With the draft GitHub release now updated, the associated artefacts can be downloaded for local testing/validation.
- When happy with the draft release, it can then be published. Upon publishing the release, it in turn publishes all the relevant artefacts to the external package managers (i.e. Docker Hub, NPM, and AWS Lambda layers).
I am very happy with the resulting CI/CD pipeline, with all the build steps being broken out into separate workflow files for readability.
These build-*.yml workflows require a supplied release version argument to correctly build the specific runtime artefact.
I had hoped to be able to keep all the build steps as deterministic Docker entries within the Makefile. However, I had issues with compiling the macOS and WASM binaries using this route. As such, the CLI and WASM both use the native GitHub Action runners’ environment. The CLI uses a workflow job matrix to compile and package the binary artefacts per target operating system.
With this pipeline now in place, easing the future process of making reliable changes to the project, it was time to step back and reflect on the project as a whole.
Conclusion
What a fun project! What was originally planned to take up to a month ended up being a multi-month personal project, where I was able to delve into not only the Rust language but also many aspects of performance benchmarking and profiling in general.
I am very happy with the resulting interpreter and the many different runtimes I was able to build along the way.
Being able to leverage Cargo’s rich package ecosystem played a big part in making this as enjoyable as it was.
I also found that linting the code with Clippy and formatting it with rsfmt greatly helped the development process.
Upon reflection, it would be good to revise the amount of Rc<RefCell<T>> usage within the Evaluator, along with refactoring parts of the Lazy Sequence implementation.
These are areas I would like to revisit after gaining more experience with Rust in future projects.
I also really enjoyed documenting the language and runtimes using MkDocs, being able to provide executable examples throughout, thanks to the WASM runtime. It sounds a little odd, but having documentation such as this makes it feel more like a ‘real’ language.
Although I managed to achieve considerable performance gains, I still think there is plenty more that can be done! Evaluation is still performed using a tree-walking interpreter, and there is only so much that can be achieved using this model of execution. If I were to delve further into performance, I would perhaps look at compiling to closures, the addition of a JIT, and even implementing a full-blown virtual machine. One thing I have realised since jumping into language design and evaluation is the sheer number of options and considerations at play, all coming with their own complexities and trade-offs.
To conclude, I look forward to using this version of santa-lang in Advent of Code calendars to come!
